#初始化输入层与竞争层神经元的连接权值矩阵definitCompetition(n , m , d):#随机产生0-1之间的数作为权值
array = random.random(size=n * m *d)
com_weight = array.reshape(n,m,d)
return com_weight
#计算向量的二范数defcal2NF(X):
res = 0for x in X:
res += x*x
return res ** 0.5#对数据集进行归一化处理defnormalize(dataSet):
old_dataSet = copy(dataSet)
for data in dataSet:
two_NF = cal2NF(data)
for i in range(len(data)):
data[i] = data[i] / two_NF
return dataSet , old_dataSet
#对权值矩阵进行归一化处理defnormalize_weight(com_weight):for x in com_weight:
for data in x:
two_NF = cal2NF(data)
for i in range(len(data)):
data[i] = data[i] / two_NF
return com_weight
#得到获胜神经元的索引值defgetWinner(data , com_weight):
max_sim = 0
n,m,d = shape(com_weight)
mark_n = 0
mark_m = 0for i in range(n):
for j in range(m):
if sum(data * com_weight[i,j]) > max_sim:
max_sim = sum(data * com_weight[i,j])
mark_n = i
mark_m = j
return mark_n , mark_m
#得到神经元的N邻域defgetNeibor(n , m , N_neibor , com_weight):
res = []
nn,mm , _ = shape(com_weight)
for i in range(nn):
for j in range(mm):
N = int(((i-n)**2+(j-m)**2)**0.5)
if N<=N_neibor:
res.append((i,j,N))
return res
#学习率函数defeta(t,N):return (0.3/(t+1))* (math.e ** -N)
#SOM算法的实现defdo_som(dataSet , com_weight, T , N_neibor):'''
T:最大迭代次数
N_neibor:初始近邻数
'''for t in range(T-1):
com_weight = normalize_weight(com_weight)
for data in dataSet:
n , m = getWinner(data , com_weight)
neibor = getNeibor(n , m , N_neibor , com_weight)
for x in neibor:
j_n=x[0];j_m=x[1];N=x[2]
#权值调整
com_weight[j_n][j_m] = com_weight[j_n][j_m] + eta(t,N)*(data - com_weight[j_n][j_m])
N_neibor = N_neibor+1-(t+1)/200
res = {}
N , M , _ =shape(com_weight)
for i in range(len(dataSet)):
n, m = getWinner(dataSet[i], com_weight)
key = n*M + m
if res.has_key(key):
res[key].append(i)
else:
res[key] = []
res[key].append(i)
return res
#SOM算法主方法defSOM(dataSet,com_n,com_m,T,N_neibor):
dataSet, old_dataSet = normalize(dataSet)
com_weight = initCompetition(com_n,com_m,shape(dataSet)[1])
C_res = do_som(dataSet, com_weight, T, N_neibor)
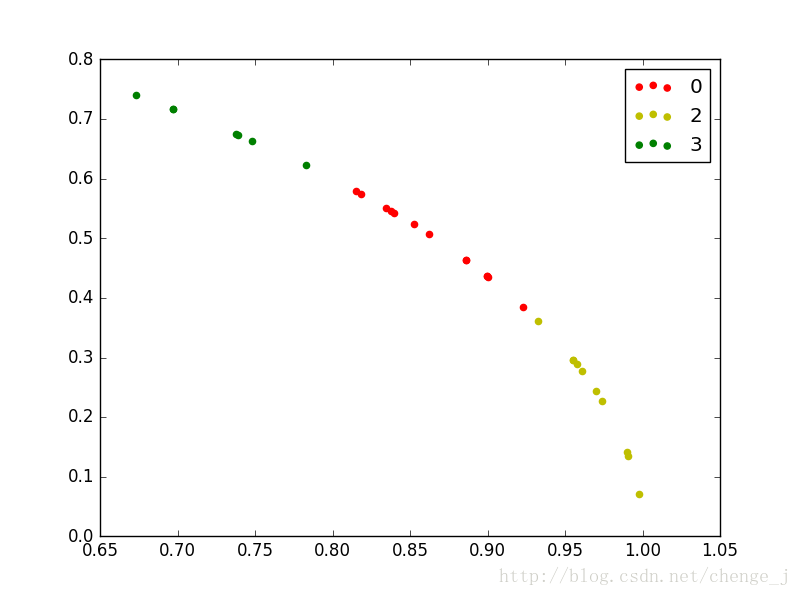
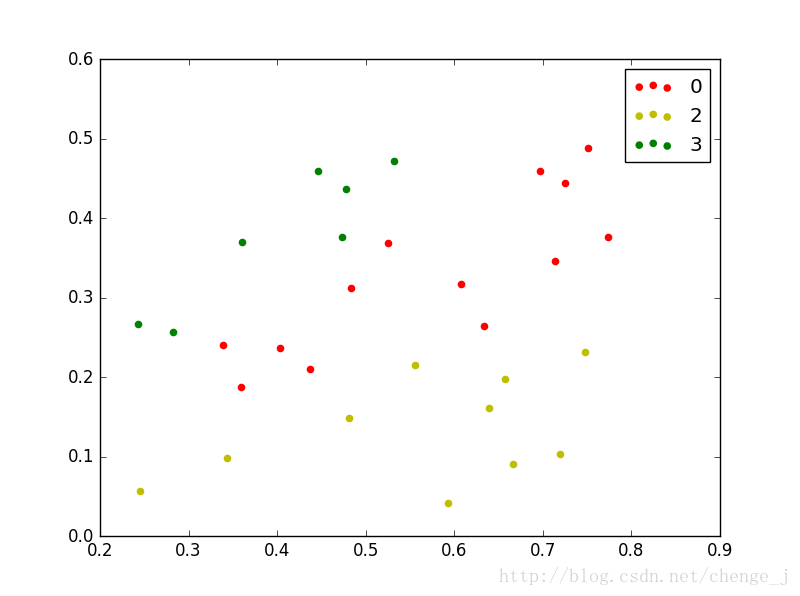
draw(C_res, dataSet)
draw(C_res, old_dataSet)
























 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









